Application web Shapash

Contribution de SixFoisSept à l’OpenSource
SixFoisSept a été créée en 2019 avec pour principes l’éthique, l’excellence opérationnelle et la conviction profonde que nous pouvions mutualiser certains de nos savoir-faire. Mutualiser nos développements et nos datas ont ainsi permis, entre autres, à toutes les collectivités de France de disposer d’un espace d’analyse et de pilotage de leurs KPI avec la mise à disposition du Cadran.
Il nous parut naturel d’apporter notre expertise à l’édifice construit par la MAIF et ses partenaires.
Contribuer au monde OpenSource en collaborant avec la MAIF sur leur outil Shapash était évident et marque de nombreuses années de collaboration entre la mutuelle et l’équipe dirigeante de SixFoisSept.
Notre expertise technique et projet acquise dans les développements du Cadran ont donc été mises à contribution pour optimiser l’interface Shapash.
Nous sommes ravis d’ouvrir et partager nos savoir-faire en proposant ces évolutions.
L’application web de Shapash
Shapash est un package Python implémenté par la MAIF qui rend le Machine Learning interprétable et compréhensible par tous.
Une application web, codée en Python Dash, est attachée à ce package pour permettre aux data scientist de comprendre rapidement leurs modèles en naviguant entre explicabilité globale et locale et visualiser la contribution des différentes variables.
L’objectif de cette application web est de vulgariser et partager les résultats auprès des utilisateurs non-spécialistes des données. Des améliorations étaient nécessaires pour rendre l’application encore plus opérationnelle. C’est dans ce contexte que SixFoisSept a pu apporter son expertise en Python Dash.
Travaux réalisés pour l’amélioration de l’application web
SixFoisSept a donc apporté son expertise Dash en contribuant à l’amélioration de l’application. Elle a ainsi a été optimisée et complétée avec l’ajout de graphiques ou de fonctionnalités détaillés ci-dessous :
Responsive design
- Amélioration du menu supérieur permettant une meilleure adaptation à l’écran (cf Figure 1).
- Ajout de titres, sous-titres et titres d’axe qui s’adaptent à la taille de l’écran pour l’ensemble des graphiques (cf Figures 2, 3, 4 et 5).
- Adaptation des étiquettes des graphiques en fonction de leur taille (cf Figures 2, 3 et 4).
Ajout de graphique ou fonctionnalités
- Création d’un onglet contenant un nouveau graphique de prédiction (cf paragraphe « True Values Vs Predicted Values et les Figures 5 et 7).
- Ajout de boutons d’explications et de fenêtres contextuelles. Shapash se voulant facile à prendre en main, ces boutons d’explications sont intuitifs et permettent aux utilisateurs de comprendre, en un clic, le fonctionnement de chaque graphique ou de l’utilisation des filtres (cf Figures 1 à 7).
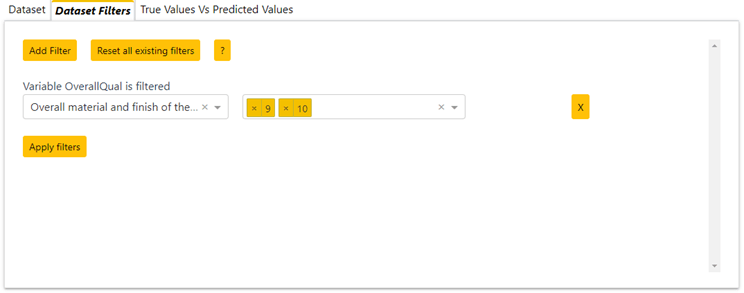
- Création d’un onglet permettant de faire des filtres sur le jeu de données (cf paragraphe Dataset Filters et la Figure 6).
Application sur un cas d’usage
Nous proposons d’illustrer ces améliorations avec un cas d’usage réalisé à partir du jeu de données public House Prices - Advanced Regression Techniques | Kaggle. Ce jeu de données comprend environ 70 variables descriptives d'une maison tant sur l'aspect et l'équipement de la maison, que la surface des pièces ou encore le nombre de cheminées, etc. Ces informations permettant d’expliquer le prix du bien immobilier.
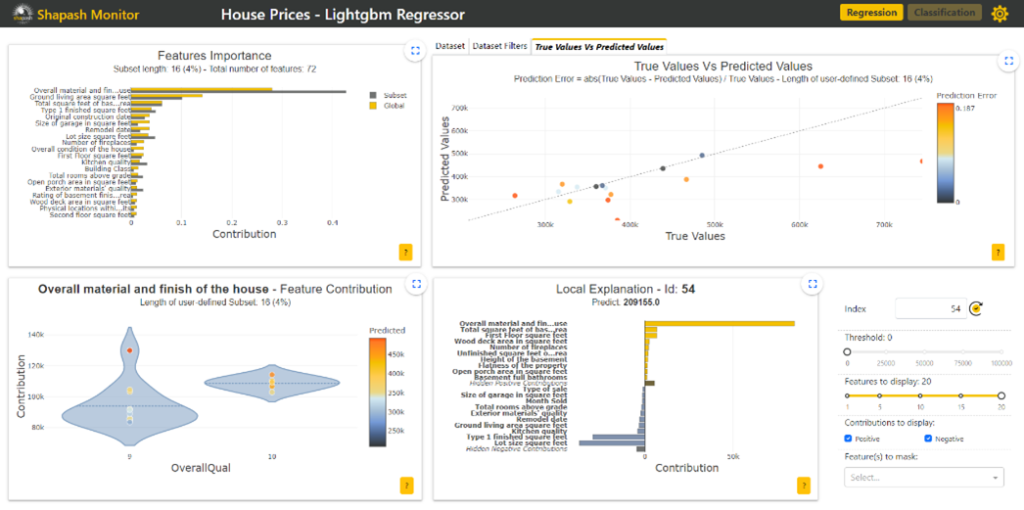
Shapash est une application Web qui comporte six parties, chacune interagissant pour faciliter l'exploration du modèle et des données.
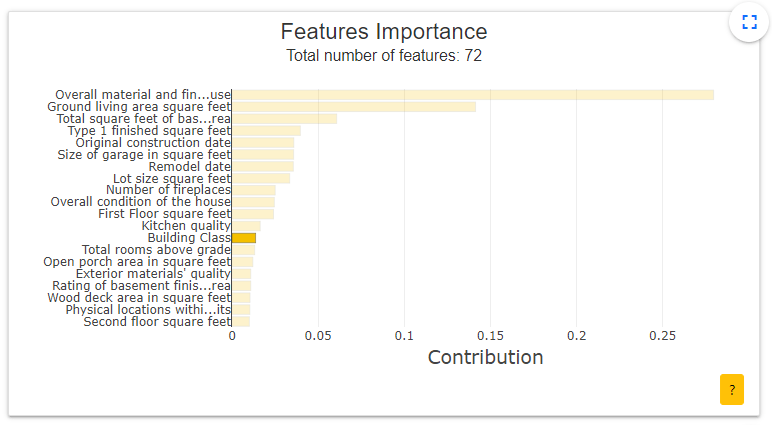
- Features Importance : Ce graphique montre à l'utilisateur la contribution de chaque variable. L'utilisateur peut cliquer sur chacune d'entre elles pour mettre à jour le graphique de contribution ci-dessous. Ici, nous avons cliqué sur la variable « building class ».
- Contribution plot : Ce graphique montre à l'utilisateur comment une variable influence la prédiction. Il peut afficher un graphique en point ou avec des violins de la dispersion de chaque contribution locale de la variable. L'utilisateur peut cliquer sur chaque point (ici la maison avec id=780) pour afficher le graphique d'explication local associé.
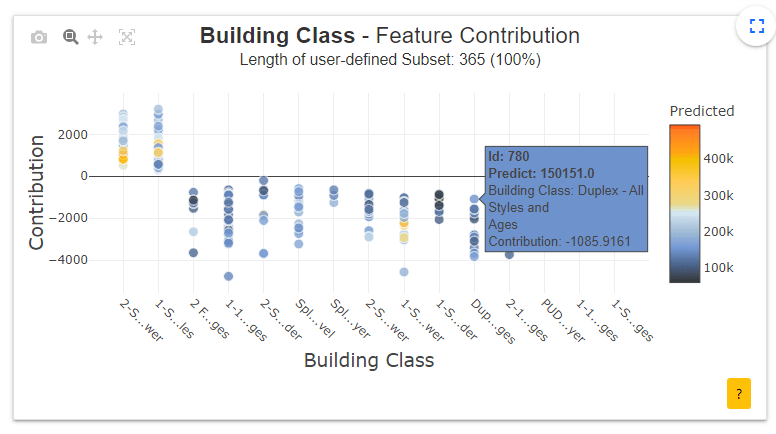
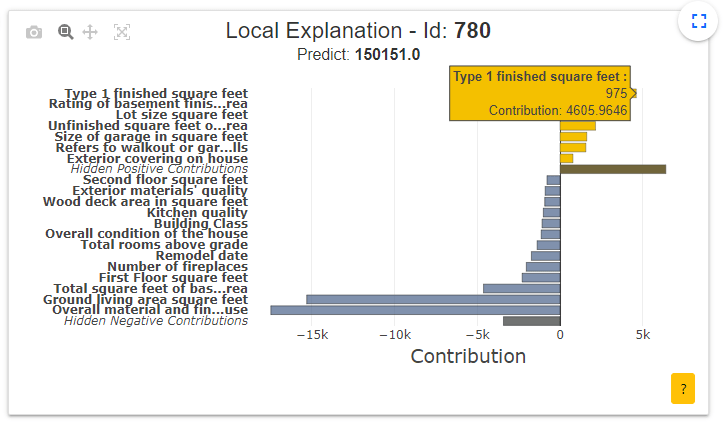
- Local explanation plot : Ce graphique permet à l’utilisateur de comprendre localement (à l’échelle d’une maison) quelles sont les variables qui contribuent le plus dans l’estimation du prix de cette maison (id=780).
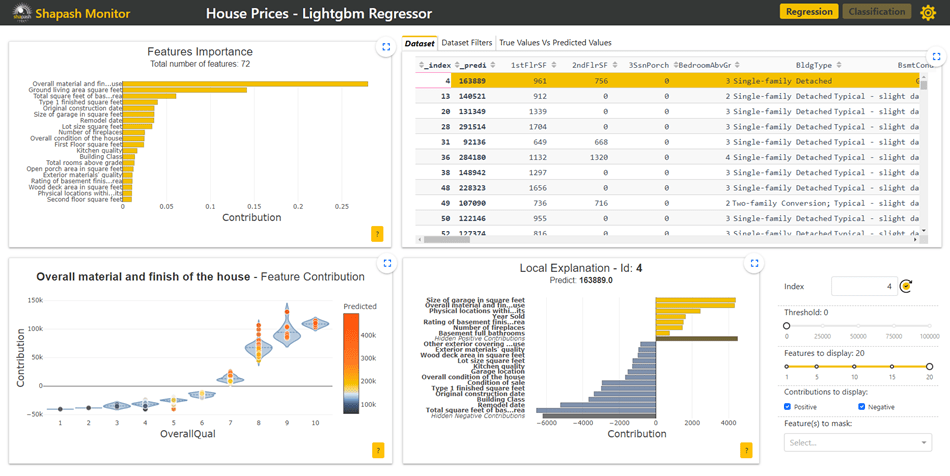
- Dataset : Cette table contient toutes les données du jeu de données des prix de maisons ainsi que les prix prédits par le modèle. L’utilisateur peut sélectionner une ligne de cette table pour observer, dans le graphique local, les variables qui contribuent le plus dans la prédiction du prix de la maison sélectionnée.
- True Values Vs Predicted Values : Ce graphique en nuage de point permet à l’utilisateur de comparer les prix prédits aux prix réels des maisons. Cela lui permet d’observer facilement les données sur lesquelles le modèle n’est pas correct et de faire un focus sur ces données en les sélectionnant.
Le prélèvement d'échantillons est un processus à grande valeur ajoutée pour mieux comprendre les modèles, leurs forces et leurs faiblesses. Cette approche est expliquée en détail dans l'article Sample Picking.
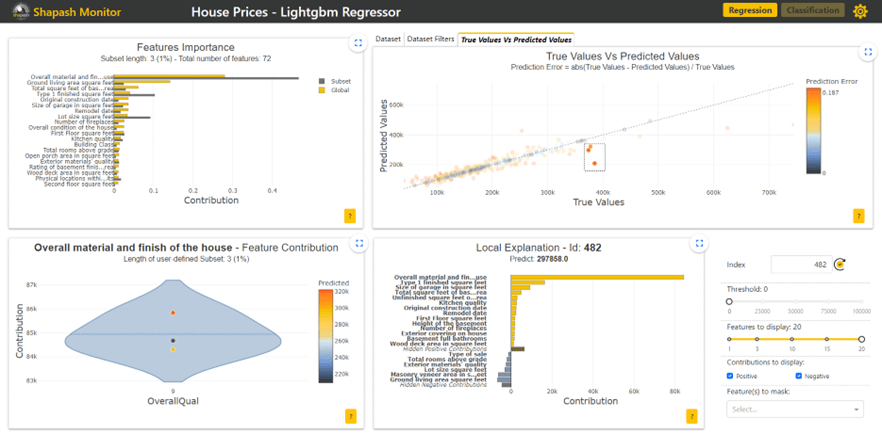
Le graphique d’explication local sur la maison id=482 indique que c’est la première variable (ensemble des matériaux et finition de la maison) qui contribue le plus au prix de cette maison. Il est possible d’ajouter un filtre sur cette variable pour analyser les maisons ayant un niveau de finition élevé comme c’est le cas ici.
- Dataset Filters : Il permet à l'utilisateur de sélectionner un sous-ensemble à l'aide de filtres et de concentrer son exploration sur celui-ci. C’est une approche complémentaire pour faire du picking et aider à mieux comprendre le modèle à l’aide d’exemples sélectionnés intelligemment par l’utilisateur. Celui-ci peut ensuite se servir de l’ensemble des graphiques pour comparer son sous-échantillon à l’ensemble des données et comprendre comment le modèle fonctionne sur ce sous-échantillon.